The textual nature of social media provides a rich corpus for analysis. These represent our efforts to extract meaning from the words we collected.
Sentiment Analysis What makes 140 characters positive or negative?
We performed sentiment analysis on our collection of tweets and posts in an attempt to extract meaningful measurements of “positivity” and “negativity” (somewhat subjectively defined). To accomplish this, we drew upon NLTK’s sophisticated textual toolset and the WordNet and SentiWordNet databases for word sense disambiguation and sentiment classification (respectively).
Note that SentiWordNet uses a semi-supervised classification mechanism that does not always produce intuitive results. Our classifications also rely on aggregations of word-wise classifications, rather than producing a “holistic” sentiment classification like that which a human would produce. The implications of this process (and some odd results that it produces) are discussed below.
To obtain useful data, we implemented a straightforward process of traversing every tweet and Facebook post we have collected, used NLTK to perform sentiment scoring and classification, and stored the results for later use. Interested readers ought to refer to our source code.
Our sentiment clasification code is (of course) available on GitHub. For those interested, the following analysis is based on exploratory analysis that is stored in the same repository.
Scoring & Classification Results
A quick analysis of classified tweets reveals some intuitive results. The following tweet was retweeted by Slate, and represents the most "negative" tweet that we observed:
The reasons for each classification appear obvious. The first is loaded with words that would intuitively be considered quite negative (insulting, dangerous), while the second explicitly lists positive words. Still, our classification method does produce some "head scratching" results. Some of the most negative tweets we retrieved were variations on the following quote from President Obama:
Obama: "Scripture tells us that we shall not oppress a stranger, for we know the heart of a stranger. We were strangers once, too."
The intention of the quote was clearly positive and meant to encourage empathy, but it was formed from an aggregation words that SentiWordNet classifies as negative. Thus, our approach is not without drawbacks, but we hope to derive at least some “signal” from our sentiment classifications.
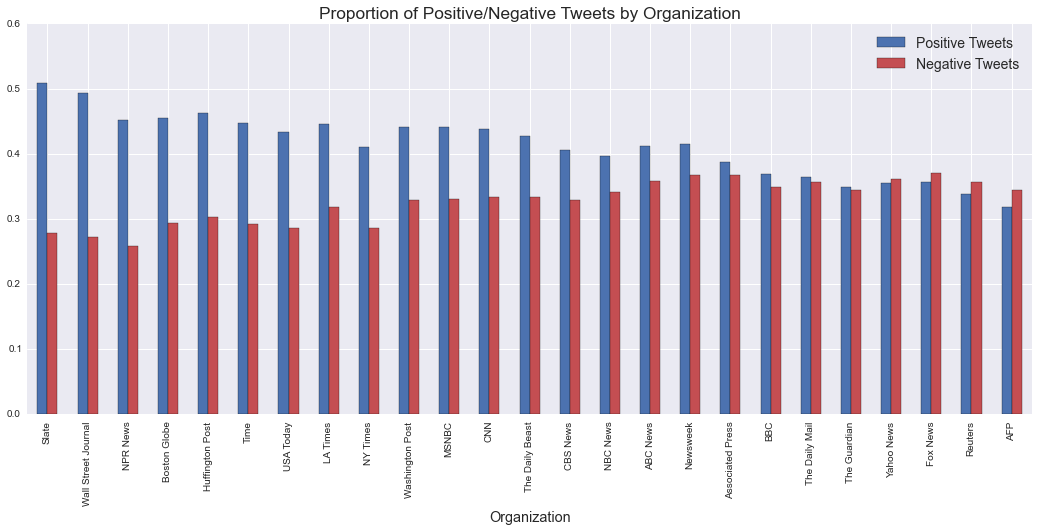
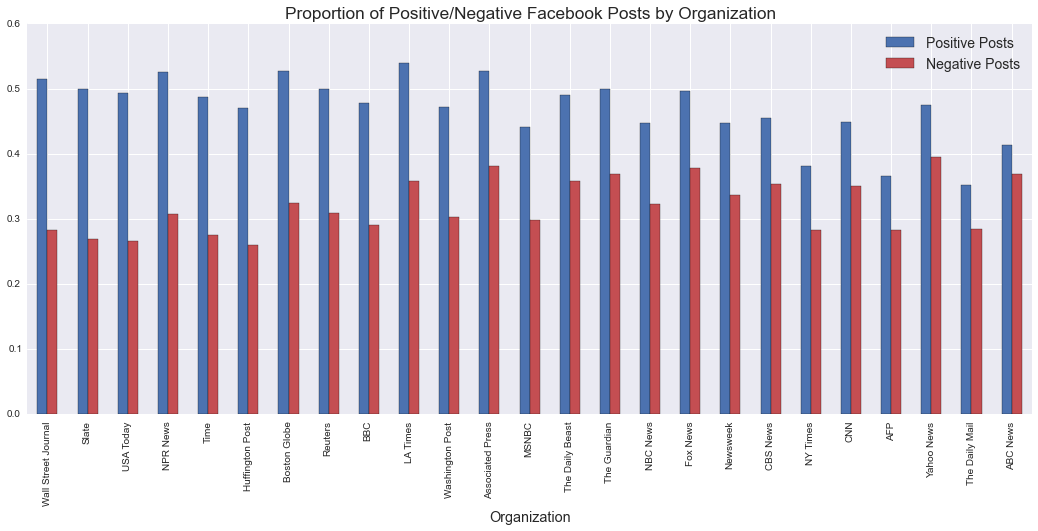
Aggregations of sentiment behavior demonstrate differences between news organizations. The following charts illustrate organizations' proportions of negative and positive posts on each social network, ordered by the difference between the two categories. Organizations with low proportions of either category may be considered more “neutral” (this does not imply journalistic neutrality).
The data above show several interesting patterns:
Several publishers show net negative posts on Twitter: more of their posts are classified as negative than positive. No organization falls into this category on Facebook.
Aggregate positivity on Facebook is much higher. This is likely attributable to the lack of a 140-character message limit: because not all words have extreme positive/negative sentiment values, or even any sentiment scores at all, many tweets are classified as neutral.
A cursory examination suggests that some organizations remain in similar sentiment "tiers" across networks (e.g., Slate, the Wall Street Journal). Others do not: Reuters (for example) is net-negative on Twitter but in the upper third of positivty on Facebook. These differences may lend insight into the organizations where presences on each network are controlled by different teams. This is not uncommon: according to its leaked 2014 Innovation Report, at the time of publication the firm's newsroom handled Twitter communications, while a business-side unit managed the company's Facebook presence.
Topic modeling is an automatic way to generate a topic for an article.
The computer selects a set of representative words from all corpus (large and structured set of texts) to construct a dictionary.
Then it selects a few words in this dictionary to generate topics. Finally, it classifies each topic to different topics.
We used two additional python libraries, nltk and gensim to auto generate the topic for each post from Twitter and Facebook. In general, there are two steps of topic generation. The first step is to lemmatize each post and build a dictionary. The second step is to build the topic model and generate topic for each post.
Lemmatizing posts Make the texts recognizable for machine.
In order to input the texts to train the topic model, we need to clean the text and transform it to the format that is understandable for a computer.
Eliminate stop words: stop words are generally only grammatical in nature but are not very important.
We remove them from posts since they are not representative.
Eliminate patterned words: some special formatted words are used in Twitter or Facebook posts, such as the words after #, @ RT...etc.
Mostly those words are not real words that we can find in the dictionary so computers cannot process them.
Lemmatization: map the different forms of a words back to its original form.
For example, "gone", "went", "goes" are mapped to "go".
Morphology: Identify the morphological features of each words in a text. We only preserve nouns because they are more representative in topics.
Dictionary: Build the dictionary of these lemmatized words. We would have the statistical summary of the words in this dictionary.
We can further eliminate words based on the words' frequency. We tuned this parameter but it did not have a significant effect because Twitter and Facebook posts are generally very short. A word filter based on how many posts a word appears is not sensible here. The idea here is to filter out words that are used in every single posts (words that are not suitable for topics) or used in a single post (words that are not generalizable to a sub-segment of posts).
Building LDA Model Train the topic model and classify the posts.
The LDA Model is essentially a classifier, which classifies the posts to different classes. Then, it gives about ten words as the name of each class. These ten words would be the topics of the posts in this class.
Build the LDA model based on the dictionary in the previous step. Some parameters require tuning in this model.
One of the most important parameter is the number of topics. We tuned this parameter to 500 topics based on the final result since the posts with the same topic have similar content.
Generate topics from the LDA model. The number of topics would be what we determined.
Put the lemmatized posts into our model. The LDA model would classify each post to one of the topics.
Top topics in Twitter and Facebook
The topics generated by LDA model are simply words with their ratio appeared in the posts classified to this topic.
In order to make the result more presentable, we manually changed the topics to more human readable ones.
Rank
Twitter Topics
Facebook Topics
1
New York
New York City
2
President Obama
Ebola in US
3
ISIS
President Obama's Immigration Policy
4
Woman Issues
Hong Kong protest
5
Highlights of the Year
Life Issues
6
Listicles
Things with Photography
7
White House
Family Related Topics
8
Ebola
Midterm Senate Elections
9
Ebola in Texas
White House
10
Ebola in Texas
ISIS
The Rank of Top 10 Topics of Twitter in each group of News Organizations
The Rank of Top 10 Topics of Facebook in each group of News Organizations
Rank in all facebook posts
Topics
Green
Blue
Teal
Red
1
New York City
11
1
3
1
2
Ebola in US
3
2
8
6
3
President Obama's Immigration Policy
12
4
5
4
4
Hong Kong Protest
301
5
42
3
5
Life Issues
17
7
6
7
6
Things with Photography
39
12
18
2
7
Family Related Topics
10
8
7
13
8
Midterm Senate Elections
18
21
1
8
9
White House
7
11
4
16
10
ISIS
132
10
2
66
11
Parents with Teenage Girls
25
20
12
14
To interpret the table: the first row shows the top Facebook post topic out of 500 topics for the 25 news organizations. In this case, it is New York City. However, for the Green group, the topic is ranked 11th out of 500 topics; for the Blue group, the topic is ranked 1 out of 500 topics; and so forth.
The different clusters/groups of news organizations have very different preference of topics:
The above table shows the top 10 topic in Facebook posts posted by the 25 news organizations. We believe that the topic modeling performed reasonably well in that we see big topics that were heavily posted on during the September - November time frame. Some of the topics that readers might recognize are Ebola, President Obama's Immigration Policy, Hong Kong Protest, Midterm Senate Elections, White House, and ISIS. We are reasonably happy with the topic modeling results and find them to be within our expectation of what news organizations were reporting on.
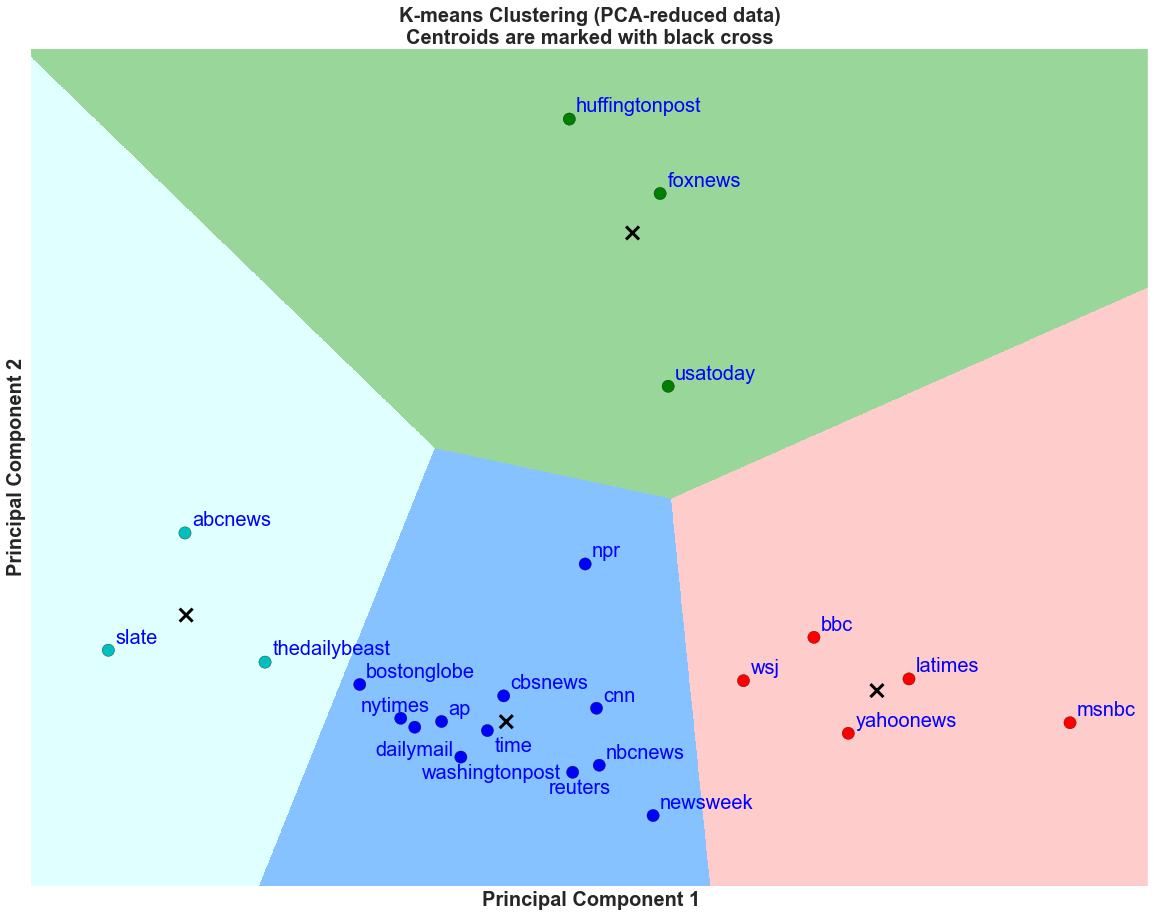
Using the results from the prior clustering analysis with social media metrics, we can also derive where the top 10 topics ranked for each of the groups. For example, from the above table, for the Green group - New York City is ranked as the 11th most posted topic while for the entire 25 news organizations, it is ranked as the most posted topic.
There are several interesting observations we can draw. First, we find the Green group's content on Facebook to be very different from the rest of the three groups. The main differences are on the topics Hong Kong Protests (ranked 301) and ISIS (ranked 132). While these topics are ranked in the top 10 for the entire 25 news organizations, these topics are not heavily reported by Huffington Post, USA Today, and Fox News. This is within our expectation of sensational news organizations compared to more serious journalistic organizations such as New York Times. In addition, the Teal group does not post much on Hong Kong Protests and the Red group does not put an emphasis on ISIS. While, for the Blue group, the ranking within the group is very similar to the overall 25 news organizations. This makes sense, since the Blue group has the majority of news organizations. We should note that Blue group is also comprised of the main traditional news outlets that would report on the more serious topics.
Rank in all Twitter posts
Topics
Green
Blue
Teal
Red
1
New York
11
1
2
3
2
President Obama
50
3
4
1
3
ISIS
14
2
95
2
4
Woman Issues
4
4
8
18
5
Highlights of the Year
8
7
5
6
6
Listicles
2
14
6
19
7
White House
6
11
7
7
8
Ebolas
48
5
31
30
9
Ebola in Texas
24
8
65
4
10
Ebola in Texas
19
6
60
28
11
Bill Cosby
34
24
3
15
The different groups of news organizations have very different preference of topics:
The top 10 topics from Twitter are a bit different from the top 10 list from Facebook. Again, New York shows up at the very top of the list. Some similar issues that were discussed heavily on Twitter were President Obama (minus the immigration policy), ISIS, White House, and Ebola. However, there were a couple of topics that were not on Facebook. For example, on Twitter we find Women's Issues, Listicles, and Bill Cosby. Furthermore, we observe due to the 140 character limit, the LDA topic model gave us concise results that were much easier to interpret.
From the above table, there are several interesting observations we can draw. First, we find the Teal group's content on twitter to be very different from the rest of the three groups. The main differences are on the topics ISIS (ranked 95), Ebola (31), and Ebola in Texas (ranked 60, 65). While these topics are ranked in the top 10 for the entire 25 news organizations, these topics are not heavily reported on by Slate, ABC News, and The Daily Beast. In addition, the topics reported by the Green group on Twitter is very different from those reported on Facebook, specifically, ISIS has now moved up from 301 to 14. However, overall, most of the top 10 topics for the entire 25 news organizations are still under represented in the Green group.
Limitations
Auto generated topics from the topic modeling might not be representative. The topic model is forced to classify the posts as the number of topics we specified, rather than to classify the posts based on their similarity. Some posts with an uncommon topic might be classified to the same group as another uncommon topic because there are too few similar posts. Some topics might be too popular so the classifier generates more than one topic for them because the model does not prefer to have too many posts classified in one topic, such as the topics “Ebola,” “Ebola in Texas” in Twitter.
Conclusion
The topic modeling results reinforce the results we found in the clustering analysis with social media metrics. From the tables above, we see that the top 10 topics for the four groups are all very different. Therefore, it is possible to conclude that there is an association of different content/topics to differences in social metrics (likes, retweets, and etc). This makes intuitive sense as there are topics that are inherently more popular than others. This is also what we observe in our data and in our news organizations clusters.