This page describes our efforts to obtain and manipulate the data that we worked with. “Janitorial work” is an important, time-consuming, and tricky requirement for drawing data science insights. You won’t find much in the way of pretty charts or cool models here, but we hope to provide a useful overview of this essential process.
Data Retrieval How to get the data we need.
To perform our analysis, we needed to turn this:
Stumbles on Ebola and ISIS could drive Obama to shake up his foreign policy team http://t.co/LH3ZuW1zI0
— The New York Times (@nytimes) October 30, 2014Into an underlying data representation (JSON) that we can work with. Twitter’s API is a breeze to work with, but features a frustrating 3,200 tweet limit when retrieving recent posts on a user’s timeline. This turned our Twitter retrievals into a two-step process: download all recent tweets for each organization, and then “scrape” older tweets for more prolific posters (e.g., @nytimes, @huffingtonpost) so as to obtain a dataset with a specific time range represented.
The first process was easy: Twython can easily retrieve recent tweets. The second process was more complex. For organizations for which we required more tweets, we used Beautiful Soup to scrape Twitter’s search results for each organization, and retrieved tweets individually. We did this (rather than saving scraped data) in order to retrieve as much information as possible about each tweet; in retrospect, we did not use any of this additional information and could have sped up the process with a pure scraping approach.
We saved all retrieved data as raw JSON (a persistent storage location may be in the cards), and carefully scheduled our “pulls” to re-retrieve more recent tweets and update our observations about their retweet and favorite counts. Finally, we ran a consolidation process to remove any duplicate records before analysis.
View our code on GitHub for retrieving recent tweets (within the 3,200 tweet limit) and scraping older tweets. The former can traverse a list of accounts; the latter must be run for a single account. This script consolidates all tweets before analysis.
Once again, we’re tasked with turning a Facebook post:
Into raw JSON that we can store and manipulate. This turns out to be an easier problem than retrieving tweets: publishers post less often on Facebook, and the company did not enforce API limits that hindered our efforts to draw a large dataset of posts. To retrieve this data, our Python scripts queried the appropriate Graph API for recent time ranges, for each organization. As with Twitter, we retrieved this data progressively (to ensure up-to-date like, comment, and share counts), and consolidated the latest data we had for each post before analysis.
Check out our post retrieval and consolidation code on GitHub.
Bitly
Much like the above steps, we relied on Bitly’s API to retrieve link clicks for all Bitly links that we found on Twitter and Facebook. Though Bitly provides very fine resolution (down to the hour) of click data (see an example), we restricted ourselves to aggregate figures. Our process was simple: we identified all such links in each post (whether they were bit.ly links or used custom domains like cnn.it) and queried the API for their click figures.
Once again, our Bitly API retrieval code is on GitHub. It reads consolidated Facebook and Twitter posts and queries the API for anything it has not yet seen (allowing it to be run progressively over time).
URL Destinations
In order to determine which links have been reposted and which have been posted on both social networks, we had to determine where each link eventually leads. We could not rely just on the raw link from each tweet/post, because many publishers alter shortened links with each post (allowing them to track clicks more easily). And even then, we could not just query Bitly’s API for the link destination, because it might traverse other pages (e.g., trib.al before landing at a destination. And finally, we wished to design a process that would be non-disruptive: it mustn’t trigger increases in Bitly click counts, nor should it disruptively query publishers’ websites.
To figure out where links lead, we designed our process to make HTTP HEAD requests (to not disrupt click counts) and avoid automatic redirections. We then followed redirections “manually” until discovering what we were confident to be the final destination of the redirection chain (the publisher’s website). Without following that URL (to avoid unnecessary requests), we moved on to the next link. This process took some time to debug but eventually allowed us to gather information about almost 200,000 social media links.
See our URL traversal code for a look at how we retrieved URL information.
Data “Wrangling” & Merging Turn raw data into into something we want.
We will now show an article example to illustrate how we are able to match articles from Twitter and Facebook posts
Twitter:
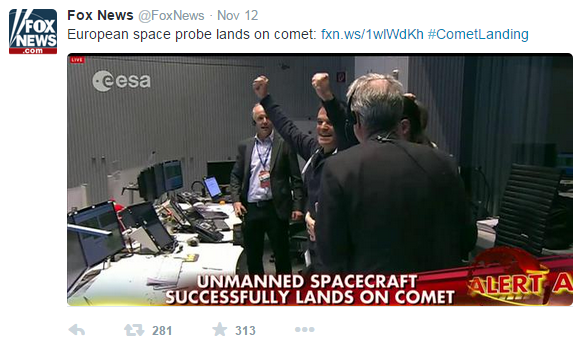
As seen above, the Twitter post has 281 retweets 313 favorites.
Twitter Bitly:
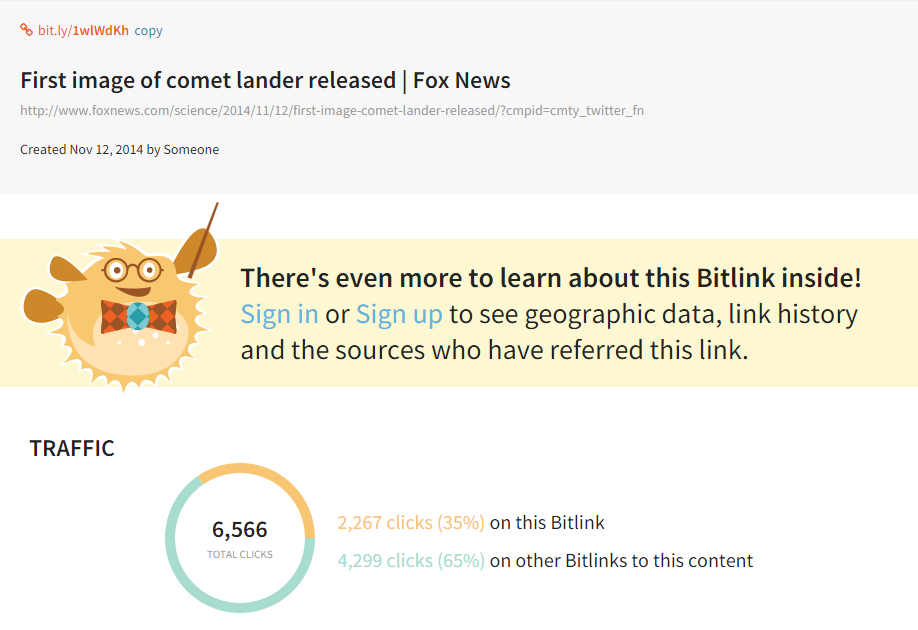
The Twitter link https://bitly.com/1wlWdKh has been clicked 2,267 times.
Facebook:
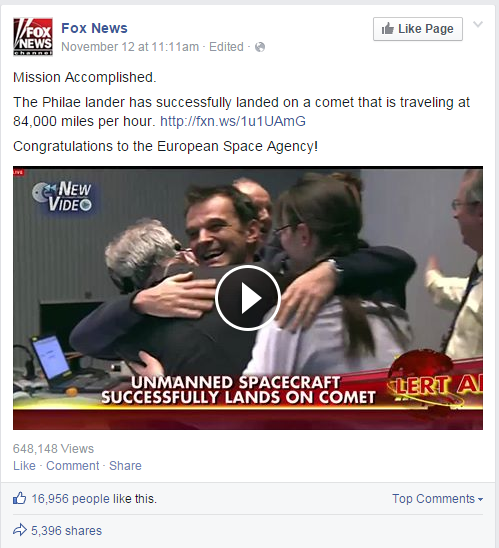
The Facebook post has 16,956 likes and 5,396 shares.
Facebook Bitly:
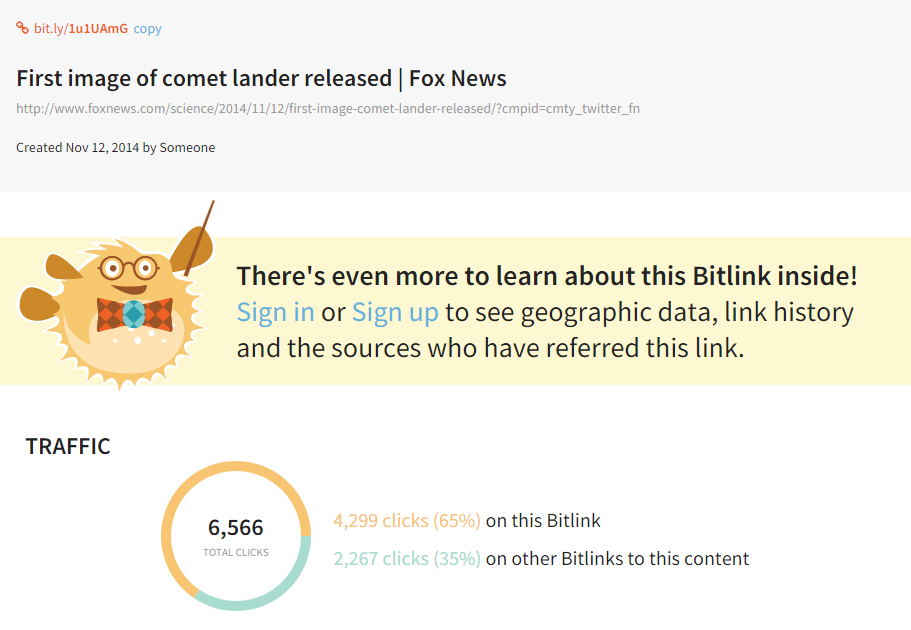
The Facebook link https://bitly.com/1u1UAmG has been clicked 4,299 times.
Data Frame
Using the information above, we are able to compile the data above into data frames such as the one shown below.
| Twitter Bitly | Retweets | Favorites | Twitter Bitly Link Clicks | Facebook Bitly | Likes | Shares | Facebook Bitly Link Clicks |
|---|---|---|---|---|---|---|---|
| https://bitly.com/1wlWdKh | 281 | 313 | 2,267 | https://bitly.com/1u1UAmG | 16,956 | 5,396 | 4,299 |
As seen from the data frame, we are able to match the Twitter and Facebook posts to the same article. Therefore, for each article, we are able to track the social metrics on both platforms and use them to form the basis for our statistical analysis.